In this vignette, we focus on Task 2 (Fair Prediction), and specifically focus on the limitation of the currently found methods in the literature to provide causally meaningful fair predictions.
Fair Predictions on COMPAS
A team of data scientists from ProPublica have shown that the COMPAS dataset from Broward County contains a strong racial bias against minorities. They are now interested in producing fair predictions \(\widehat{Y}\) on the dataset, to replace the biased predictions. They first load the COMPAS data:
# load the datadat <-get(data("compas", package ="faircause"))knitr::kable(head(dat), caption ="COMPAS dataset.")
COMPAS dataset.
sex
age
race
juv_fel_count
juv_misd_count
juv_other_count
priors_count
c_charge_degree
two_year_recid
Male
69
Non-White
0
0
0
0
F
0
Male
34
Non-White
0
0
0
0
F
1
Male
24
Non-White
0
0
1
4
F
1
Male
23
Non-White
0
1
0
1
F
0
Male
43
Non-White
0
0
0
2
F
0
Male
44
Non-White
0
0
0
0
M
0
# load the metadatamdat <-get_metadata("compas")
To produce fair predictions, they first experiment with four different classifiers.
WARNING:root:No module named 'tempeh': LawSchoolGPADataset will be unavailable. To install, run:
pip install 'aif360[LawSchoolGPA]'
WARNING:root:No module named 'tensorflow': AdversarialDebiasing will be unavailable. To install, run:
pip install 'aif360[AdversarialDebiasing]'
WARNING:root:No module named 'tensorflow': AdversarialDebiasing will be unavailable. To install, run:
pip install 'aif360[AdversarialDebiasing]'
Are the methods successful at eliminating discrimination?
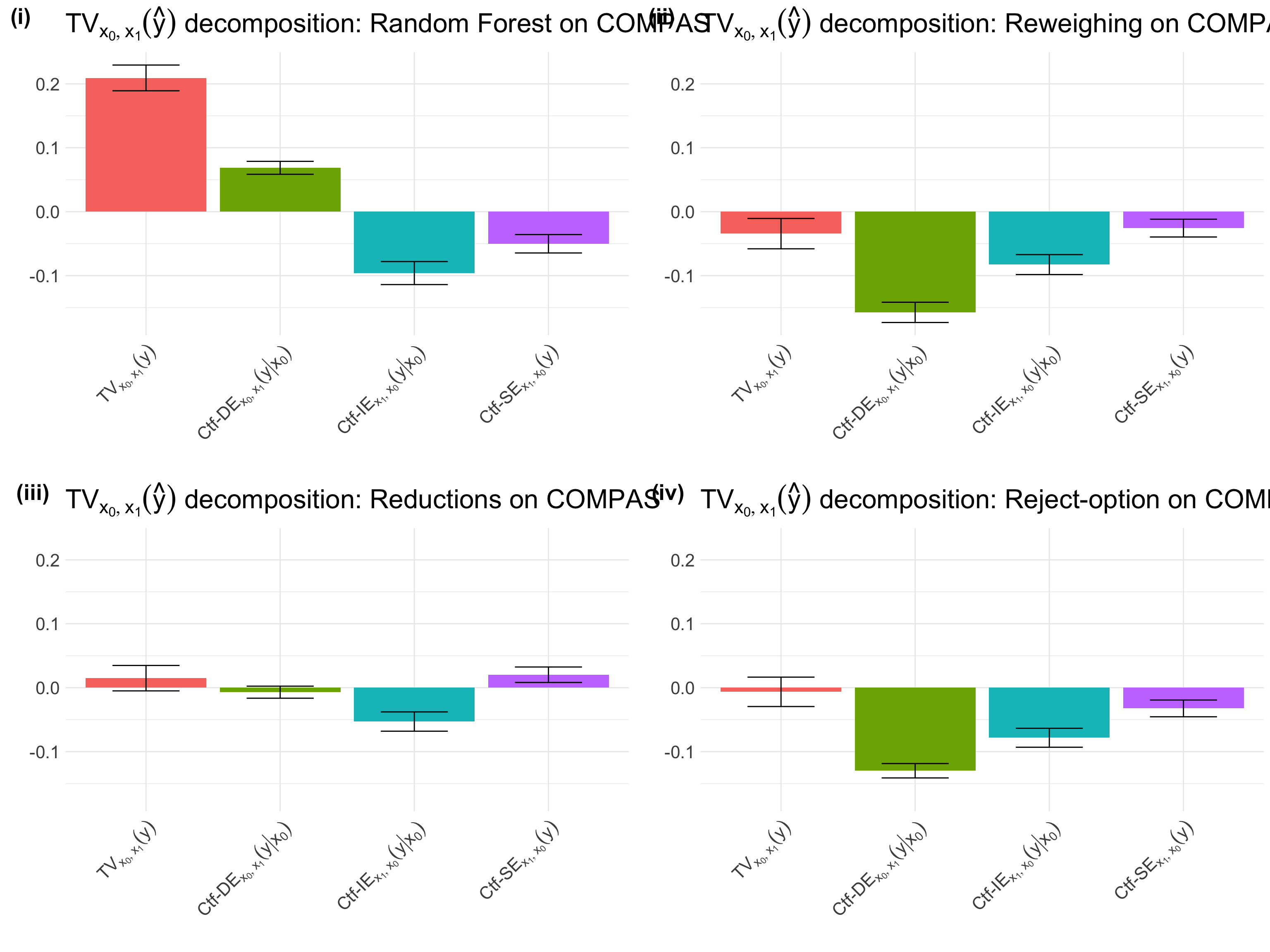
The fair prediction algorithms used above are intended to set the TV measure to \(0\). After constructing these predictors, the ProPublica team made use of the Fairness Cookbook, to inspect the causal implications of the methods. Following the steps of the Fairness Cookbook, the team computes the TV measure, together with the appropriate measures of direct, indirect, and spurious discrimination. We can now visualize these decompositions in Figure 1.
Figure 1: Fair Predictions on the COMPAS dataset.
The ProPublica team notes that all methods substantially reduce the \(\text{TV}_{x_0,x_1}(\widehat{y})\), however, the measures of direct, indirect, and, spurious effects are not necessarily reduced to \(0\), consistent with the Fair Prediction Theorem.
How to fix the issue?
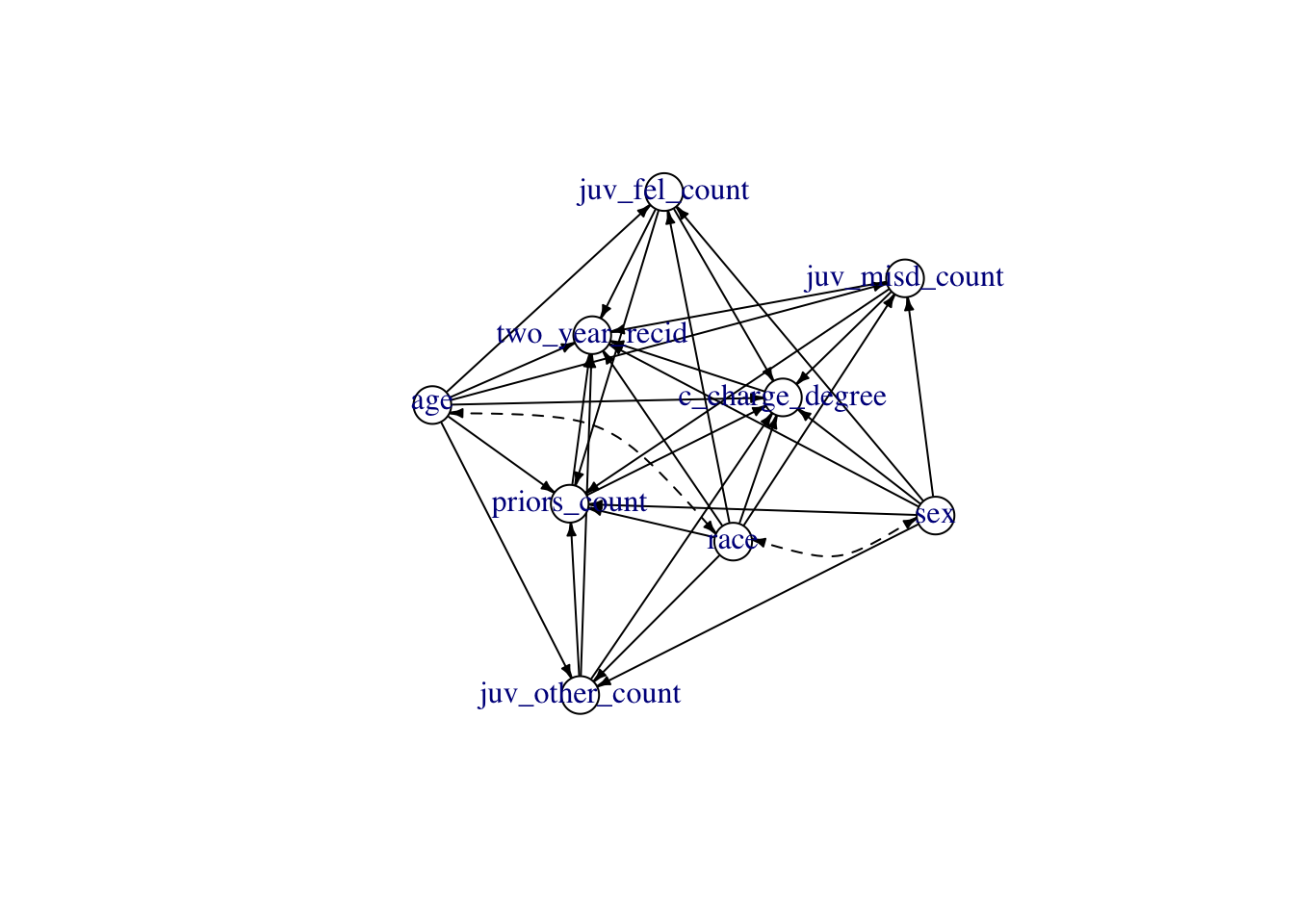
To produce causally meaningful fair predictions, we suggest using the fairadapt package (Plečko and Meinshausen 2020; Plečko, Bennett, and Meinshausen 2021). In particular, the package offers a way of removing discrimination which is based on the causal diagram. In this application, we are interested in constructing fair predictions that remove both the direct and the indirect effect. Firstly, we obtain the adjacency matrix representing the causal diagram associated with the COMPAS dataset:
After loading the causal diagram, we perform fair data adaptation:
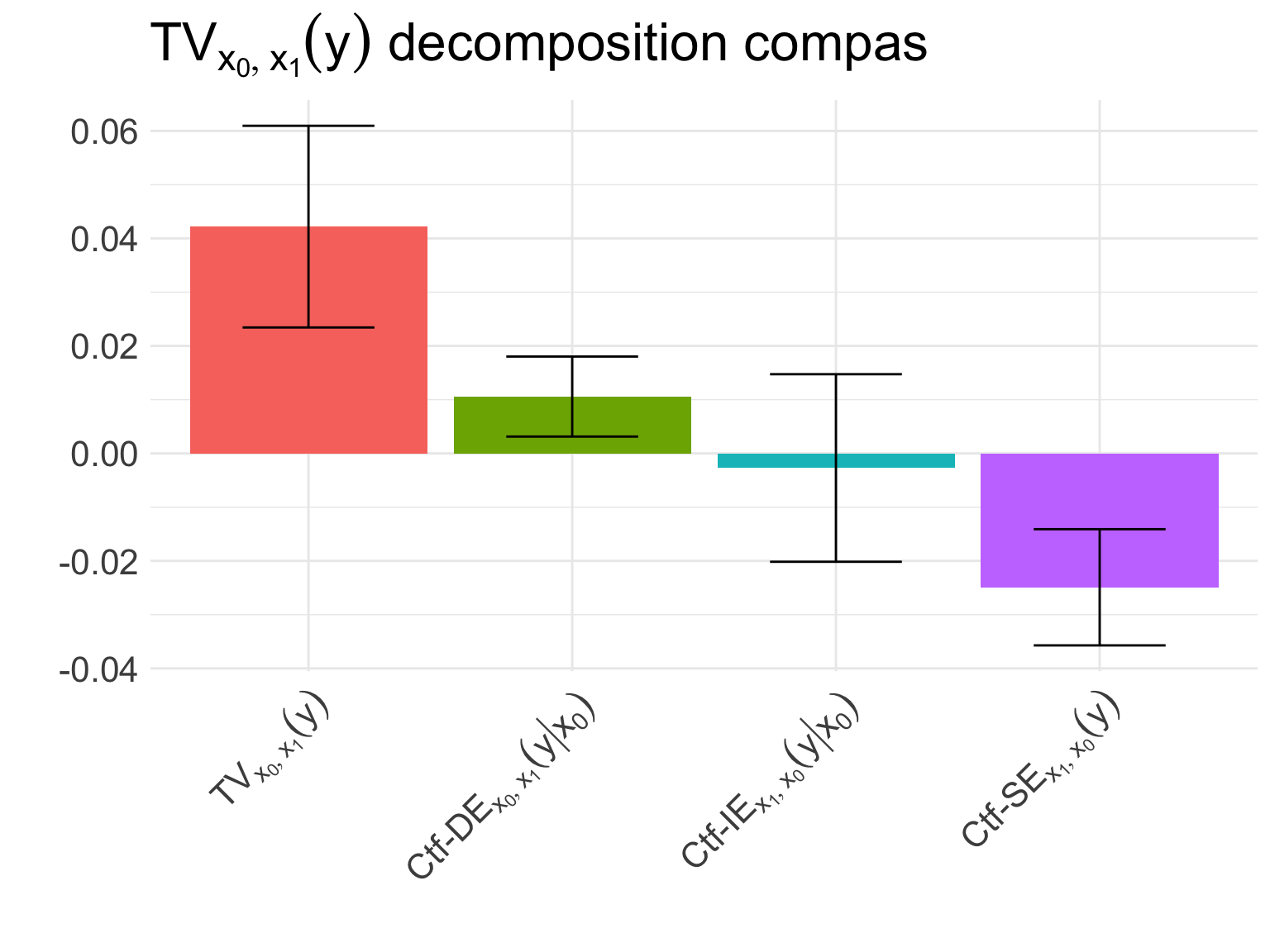
fdp <- fairadapt::fairadapt(two_year_recid ~ ., prot.attr ="race",train.data = dat, adj.mat = adj.mat)# obtain the adapted dataad_dat <- fairadapt:::adaptedData(fdp)ad_dat$race <- dat$race# obtain predictions based on the adapted dataadapt_oob <-ranger(two_year_recid ~ ., ad_dat,classification =TRUE)$predictionsad_dat$two_year_recid <- adapt_oob# decompose the TV for the predictionsdat.fairadapt <- datdat.fairadapt$two_year_recid <- adapt_oobfairadapt_tvd <-fairness_cookbook( ad_dat, mdat[["X"]], mdat[["W"]], mdat[["Z"]], mdat[["Y"]], mdat[["x0"]], mdat[["x1"]])# visualize the decompositionfairadapt_plt <-autoplot(fairadapt_tvd, decompose ="xspec", dataset = dataset) +xlab("") +ylab("")fairadapt_plt
Figure 2: Fair Data Adaptation on the COMPAS dataset.
Figure 2 shows how the fairadapt package can be used to provide causally meaningful predictions that remove both direct and indirect effects.
References
Agarwal, Alekh, Alina Beygelzimer, Miroslav Dudík, John Langford, and Hanna Wallach. 2018. “A Reductions Approach to Fair Classification.” In International Conference on Machine Learning, 60–69. PMLR.
Kamiran, Faisal, and Toon Calders. 2012. “Data Preprocessing Techniques for Classification Without Discrimination.”Knowledge and Information Systems 33 (1): 1–33.
Kamiran, Faisal, Asim Karim, and Xiangliang Zhang. 2012. “Decision Theory for Discrimination-Aware Classification.” In 2012 IEEE 12th International Conference on Data Mining, 924–29. IEEE.
Plečko, Drago, Nicolas Bennett, and Nicolai Meinshausen. 2021. “Fairadapt: Causal Reasoning for Fair Data Pre-Processing.”arXiv Preprint arXiv:2110.10200.
Plečko, Drago, and Nicolai Meinshausen. 2020. “Fair Data Adaptation with Quantile Preservation.”Journal of Machine Learning Research 21: 242.