devtools::install_github("dplecko/CFA")COMPAS Analysis - A Causal Approach
Abstract
In this submission, we analyze the predictions from the COMPAS tool used in Broward County, Florida. In particular, we expand on the analysis performed by ProPublica in 2016, complementing it with tools of causal inference. Our analysis is performed in three steps. Firstly, we compute the disparity between demographic groups in the actual, true recidivism rates, and provide a causal explanation for how this disparity arose in practice. Secondly, we compute the disparity between groups for the predictions produced by Northpointe, Inc., and demonstrate that the predictions have a different causal explanation, directly pointing to discrimination. Finally, in the last step, we provide a causal explanation for the disparity of Northpointe’s predictions in the group of individuals who did not recidivate - which shows once again that there is a discriminatory effect of race on the predictions. The implication of our analysis is that there exists prima facie evidence against Northpointe, who discriminated against minority groups purely based on race (and not on other, race related features), which is prohibited by the Equal Protection clause of the 14th Amendment.
Introduction
Across United States, courts are using algorithms to predict which of the defendants are likely to recidivate and re-offend. As is becoming apparent in the literature on fair machine learning, algorithms do not have any ethical or moral values a priori, and they are capable of learning, or even amplifying the existing societal bias. If left unattended, such algorithms could lead to the perpetuation of unfairness, raising a serious concern about the impact of AI on socially important questions in the long term.
In their seminal work from 2016 (Larson et al. 2016), the team from ProPublica (an independent, non-profit newsroom), analyzed data from a commercial tool called Correctional Offender Management Profiling for Alternative Sanctions (COMPAS), which was developed by Northpointe, Inc. (the company is today known as Equivant). The analysis was performed on a large number of individuals from Broward County, Florida, and compared the recidivism predictions produced by COMPAS with those that actually occurred in practice. The findings of their analysis sent alarm bells ringing to everyone concerned about issues of racial injustice. In particular, the ProPublica team demonstrated, among other things, that:
- black defendants who did not recidivate over a two-year period were nearly twice as likely to be classified as higher risk compared to their white counterparts,
- white defendants who did recidivate over a two-year period were labeled as low risk twice as often as black re-offenders.
The above mentioned disparities observed by ProPublica are a starting point of an important investigation. What their analysis did not investigate is the causal explanation of how the disparities arose. In particular, using the language of causal models, we provide such an explanation as follows. For the observed disparity between the groups, we quantify how much of the disparity can be explained by:
- the direct causal effect of race on the outcome (not explained by other features),
- the indirect causal effect of race on previous offenses and degree of charge, which in turn influence the outcome,
- the confounded effect of race, which is associated with age and sex in the dataset, both of which are predictive of outcome.
We remark here that our causal analysis should be thought of manipulating the ``signals” of race, or its perception, rather than race itself, which is an immutable characteristic of every individual (Weinberger 2022; Greiner and Rubin 2011).
The three steps of our analysis are the following: A. we first look at the causal explanation of the two-year recidivism rates \(Y\), which will help us understand the causal effects of race in the real world, A. we then look at the causal explanation of the Northpointe’s predictions, which will help us understand the causal effects of the predicted world, A. finally, we look at the causal explanation of the Northpointe’s predictions when subsetting to only the group of individuals who did not recidivate over a two-year period; such an analysis will help us understand how Northpointe’s predictions causally treat individuals who do not re-offend.
We now introduce the methodology used in our analysis, which is implemented in the faircause R-package. The package can be installed using:
Methodology
In this manuscript, we analyze the same dataset as the ProPublica team. We apply tools of causal reasoning (Pearl 2000). In particular, we follow the approach of Causal Fairness Analysis described in (Plecko and Bareinboim 2022). First, we start by constructing a causal graphical model of the dataset. The dataset consists of the following information:
- the protected attribute \(X\), in this case race (for simplicity, race has two levels, corresponding to the majority group, and all other minority groups put together),
- the confounding variables \(Z\), in this case age and sex,
- the mediator variables \(W\), in this case juvenile and prior offense counts, and the degree of criminal charge,
- two outcome variables, \(Y\) and \(\hat{Y}\), which represent the two-year recidivism and the Northpointe’s prediction, respectively.
Therefore, our dataset looks like:
| sex | age | race | juv_fel | juv_misd | juv_other | priors | charge | two_year_recid | northpointe |
|---|---|---|---|---|---|---|---|---|---|
| Male | 69 | Minority | 0 | 0 | 0 | 0 | F | 0 | 0 |
| Male | 34 | Minority | 0 | 0 | 0 | 0 | F | 1 | 0 |
| Male | 24 | Minority | 0 | 0 | 1 | 4 | F | 1 | 0 |
| Male | 23 | Minority | 0 | 1 | 0 | 1 | F | 0 | 1 |
| Male | 43 | Minority | 0 | 0 | 0 | 2 | F | 0 | 0 |
| Male | 44 | Minority | 0 | 0 | 0 | 0 | M | 0 | 0 |
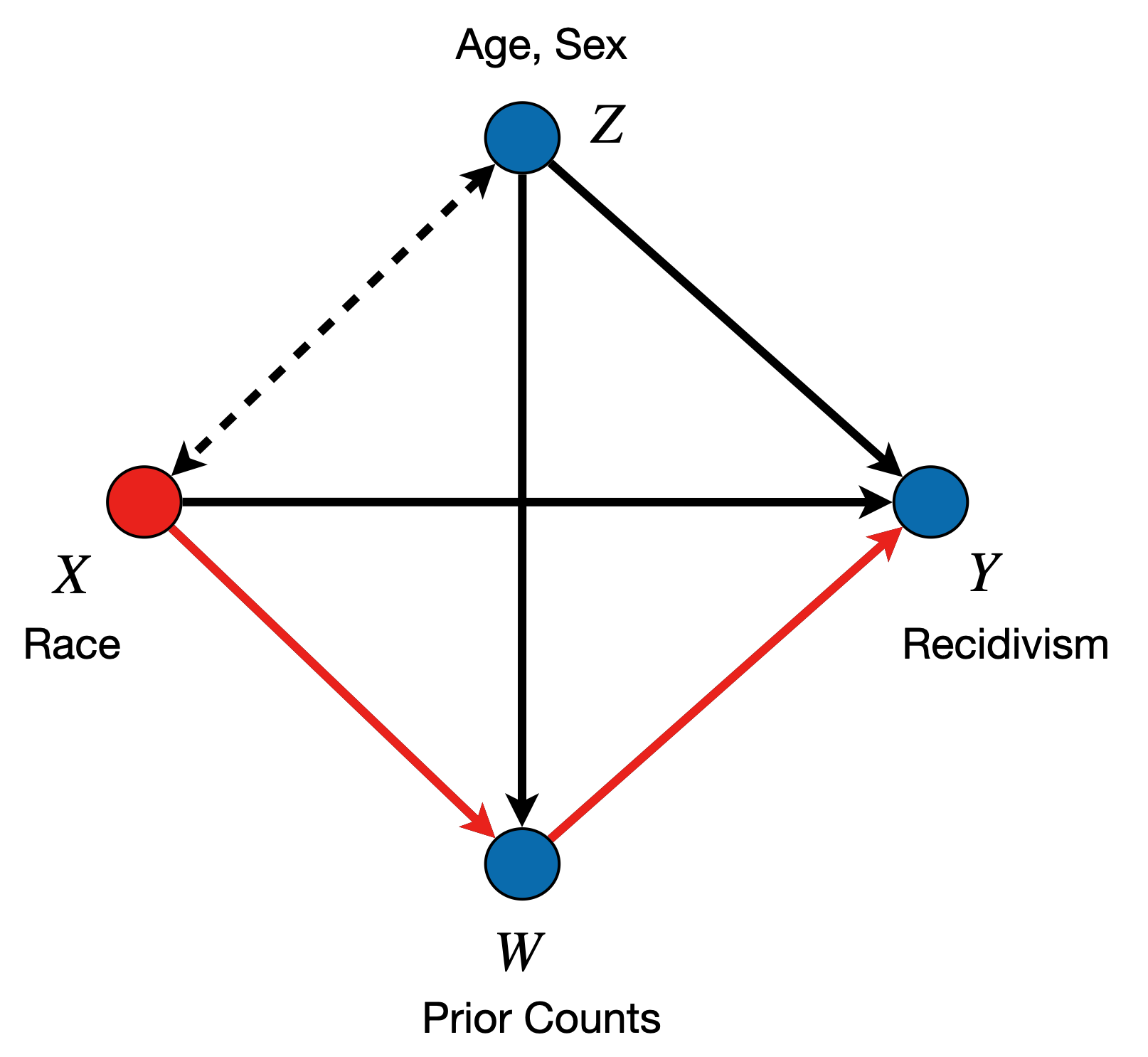
The causal diagram of the above dataset is shown in Figure 1, which shows how different variables influence each other. The causal graphical model can be interpreted as follows:
- there is a bidirected edge between race \(X\) and demographic variables \(Z\), which are correlated in the dataset; the edge represents either a confounding mechanism through some historical context, or a selection bias mechanism,
- there is a directed edge from \(X\) to \(W\), \(Y\), which allows for the possibility that race has an effect on the prior offense counts, and the recidivism outcome; the edge can represent various types of bias, such as a bias in policing or the judicial system against minority groups.
- there are directed edges, from \(Z, W\) into the outcome \(Y\), allowing for the possibility that prior offense counts or demographic features influence recidivism,
- there is a directed edge from \(Z\) to \(W\), which represents the effect of demographic variables on prior offense counts.



Based on the graphical model, and using the methodology of decomposing variations which is introduced in Equation 1 shortly, we can decompose the parity gap between the majority and minority groups, into its direct, indirect, and confounded parts. The parity gap is defined as the difference in conditional expectations between the groups, namely
\[ \begin{equation} \text{PG}_{x_0, x_1}(y) = P(Y = 1\mid X = x_1) - P(Y = 1 \mid X = x_0). \end{equation} \tag{1}\]
From a causal viewpoint, we can decompose the parity gap in the following way: \[ \begin{equation} \text{PG}_{x_0, x_1}(y) = \underbrace{\text{DE}}_{\text{race effect}} + \underbrace{\text{IE}}_{\text{prior counts effect}} + \underbrace{\text{CE}}_{\text{age/sex effect}}, \end{equation} \] where DE, IE, and CE stand for direct, indirect, and confounded effects, respectively. The graphical visualizations of the thre effects are shown in Figure 2, Figure 3, and Figure 4, respectively. After decomposing the parity gap for two-year recidivism \(Y\) (Experiment A), we also decompose it for the Northpointe’s predictions \(\hat{Y}\) (Experiment B), and finally decompose it for the \(\hat{Y}\) in the subgroup of individuals who did not recidivate, i.e. with \(Y = 0\) (Experiment C).
Results
In this section, we report the results of the three experiments: A) explaining the disparity in true recidivism; B) explaining disparity in Northpointe’s predictions; C) explaining disparity in Northpointe’s prediction for defendants who did not recidivate (\(Y = 0\)).
A: Explaining disparity in recidivism
As our starting point, we first compute the disparity between groups in two-year recidivism:
tapply(data$two_year_recid, data$race, mean)Majority Minority
0.393643 0.480042 Based on this information, we can compute that: \[\begin{equation}
\text{PG}_{x_0, x_1}(y) = 48\% - 39.5\% = 8.5\%.
\end{equation}\] We then apply the fairness_cookbook() functionality from the R-package, and choose two_year_recid (\(Y\)) as the outcome of interest:
X <- "race"
Z <- c("age", "sex")
W <- c("juv_fel", "juv_misd", "juv_other", "priors", "charge")
Y <- c("two_year_recid")
two_year <- fairness_cookbook(data, X = X, W = W, Z = Z, Y = Y,
x0 = "Majority", x1 = "Minority")
two_yearfaircause object:
Attribute: race
Outcome: two_year_recid
Confounders: age,sex
Mediators: juv_fel,juv_misd,juv_other,priors,charge After performing the decomposition we can visualize how the decomposition, as shown in Figure 5.
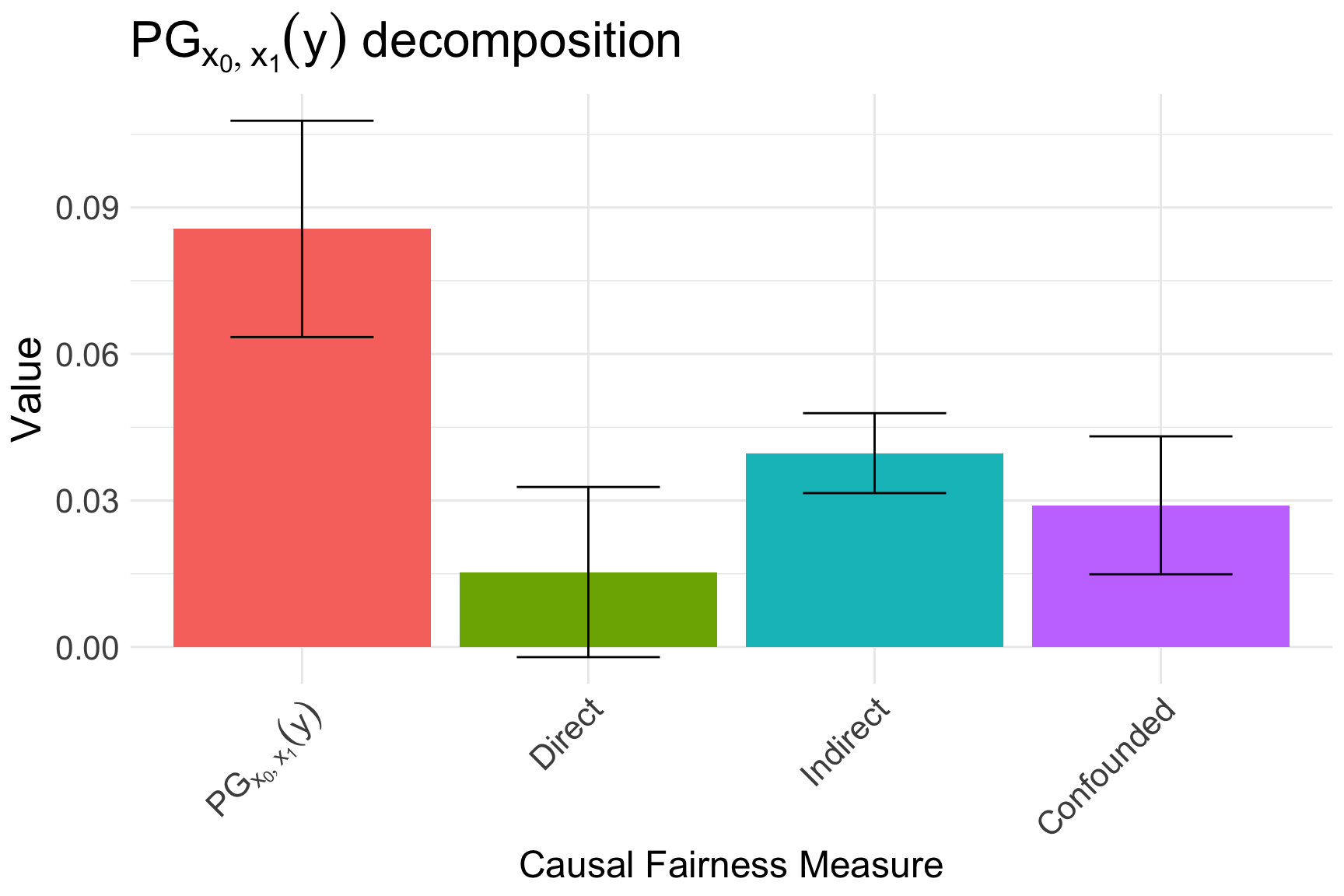
Therefore, we have the first crucial result: \[ \begin{equation} \text{PG}_{x_0, x_1}(y) = \underbrace{1.5\%\;(\pm 1.8\%)}_{\text{race effect}} + \underbrace{4\%\;(\pm 0.8\%)}_{\text{prior counts effect}} + \underbrace{3\%\;(\pm 1.4\%)}_{\text{age/sex effect}}. \end{equation} \] Important to note is that race does not have a statistically significant direct effect on outcome.
B: Explaining disparity in Northpointe’s recidivism predictions
Our next step is to analyze the causal decomposition of the Northpointe’s predictions.
tapply(data$northpointe, data$race, mean) Majority Minority
0.3480033 0.5174370 Therefore, we can compute that: \[
\begin{equation}
\text{PG}_{x_0, x_1}(\hat{y}) = 52\% - 35\% = 17\%.
\end{equation}
\] Firstly, we notice that the disparity in the predicted outcome is larger than in the true outcome. But crucially, the question is how this disparity in predicted outcome arises from a causal point of view. We again apply the fairness_cookbook(), this time choosing northpointe (\(\hat{Y}\)) as the outcome of interest:
Yhat <- "northpointe"
north_decompose <- fairness_cookbook(data, X = X, W = W, Z = Z, Y = Yhat,
x0 = "Majority", x1 = "Minority")
autoplot(north_decompose, decompose = "xspec", signed = FALSE) +
ggtitle(TeX("$PG_{x_0, x_1}(\\hat{y})$ decomposition"))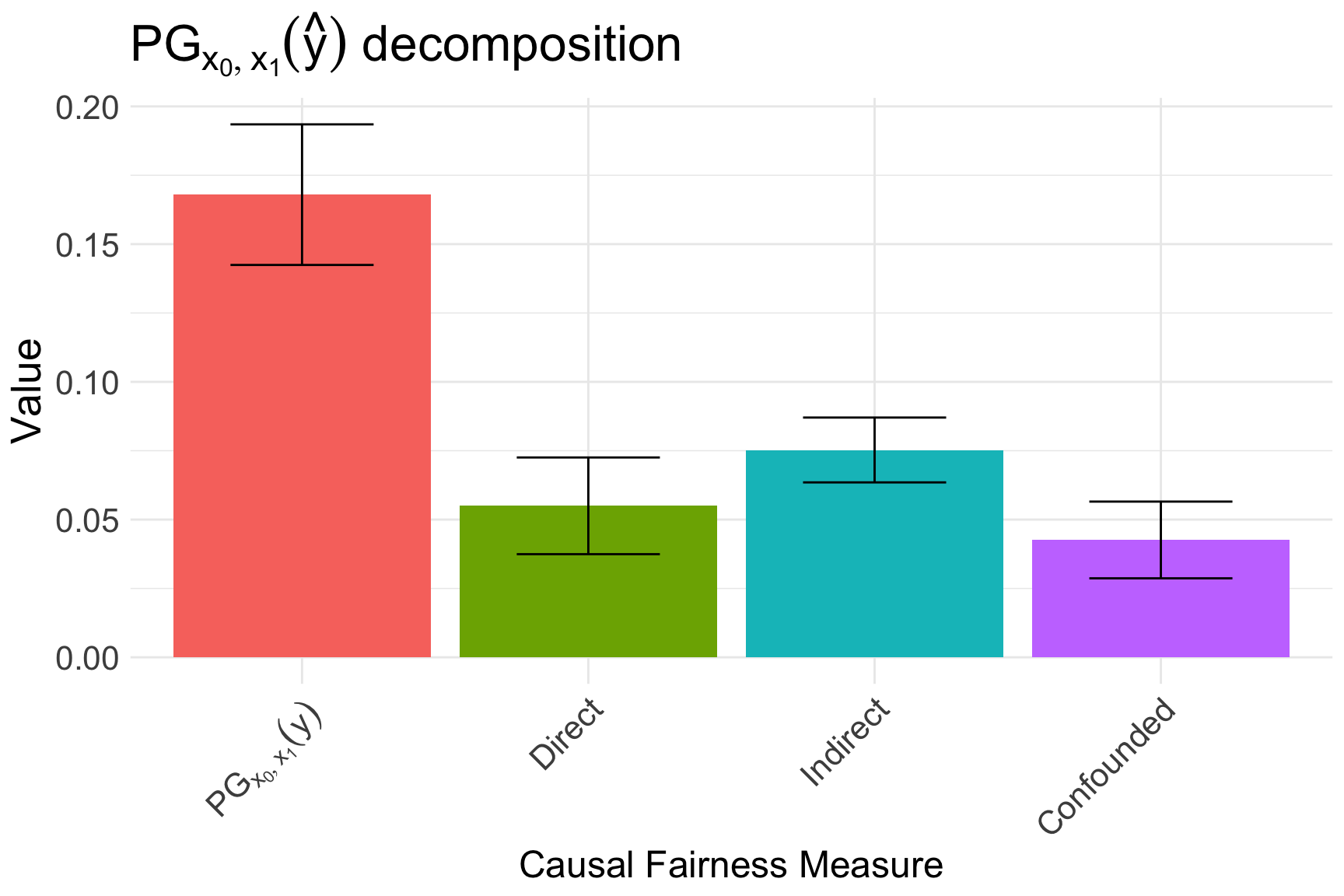
In particular, we obtain that: \[ \begin{equation} \text{PG}_{x_0, x_1}(\hat{y}) = \underbrace{5.5\% \;(\pm 1.75\%)}_{\text{race effect}} + \underbrace{7.5\% \;(\pm 1.2\%)}_{\text{prior counts effect}} + \underbrace{3\%\;(\pm 1.5\%)}_{\text{age/sex effect}}. \end{equation} \] The decomposition is also visualized in Figure 6. Crucially, we find that race does have a statistically significant direct effect on Northpointe’s predictions. Furthermore, race by itself explains one third of the observed disparity.
C: Explaining disparity in Northpointe’s recidivism predictions for those who did not recidivate
In the final step, we again perform a decomposition of a disparity, but this time within the group of individuals who did not recidivate. Similarly as before, we can distinguish the direct, indirect, and spurious effects in this disparity. However, the quantity we are decomposing is not the parity gap, but the error rate related to the equality of opportunity criterion, i.e., \[ \begin{equation} \text{ER}_{x_0, x_1}(\hat{y} | y = 0) = P(\hat{Y} = 1 \mid X = x_1, Y = 0) - P(\hat{Y} = 1 \mid X = x_0, Y = 0). \end{equation} \] In words, we compare the proportion of minority individuals who are flagged as high risk, but did not recidivate, to the proportion of majority individuals who are flagged as high risk but did not recidivate. We can compute this as:
no_recid <- data$two_year_recid == 0
tapply(data$northpointe[no_recid], data$race[no_recid], mean) Majority Minority
0.2345430 0.3769697 Therefore, we obtained that: \[
\begin{equation}
\text{ER}_{x_0, x_1}(\hat{y} \mid y = 0) = 38\% - 23\% = 15\%.
\end{equation}
\] In words, from defendants who do no recidivate, the minority group defendants are 15% more likely to be labeled as high risk. Once again, we can obtain a causal decomposition, but this time of the \(\text{ER}_{x_0, x_1}(\hat{y} \mid y = 0)\) measures. For this purpose, we use the fairness_cookbook_eo() functionality:
eo_decompose <- fairness_cookbook_eo(data, X = X, W = W, Z = Z, Y = Y,
Yhat = Yhat, x0 = "Majority", x1 = "Minority",
ylvl = 0)
autoplot(eo_decompose, decompose = "xspec", signed = FALSE, eo = TRUE)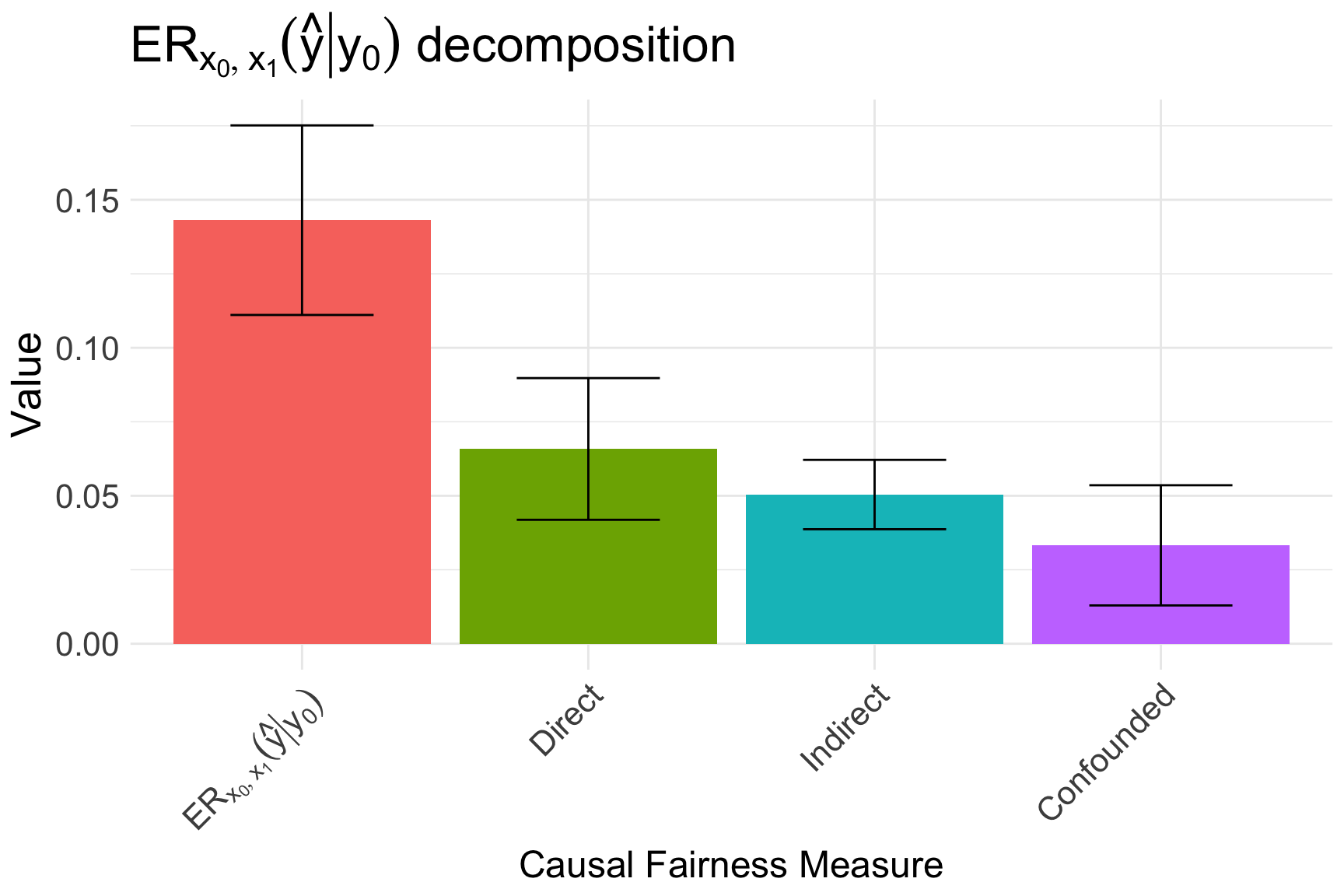
The visualization of the decomposition is shown in Figure 7 and can be written mathematically as: \[\begin{equation} \text{ER}_{x_0, x_1}(\hat{y} \mid y = 0) = \underbrace{6.8\% \;(\pm 2\%)}_{\text{race effect}} + \underbrace{5\% \;(\pm 1.3\%)}_{\text{prior counts effect}} + \underbrace{3\%\;(\pm 2\%)}_{\text{age/sex effect}}. \end{equation}\] We conclude that there is a direct effect of race on the prediction even within the group of individuals who do not recedivate. Race explains more than one third of the observed disparity in the group.
Discussion
Key Findings
The analysis presented in this submission consists of three steps, with each of the steps demonstrating a specific causal explanation. The first step of the analysis demonstrates that the direct effect of race is not statistically significant when analyzing the true recidivism rates. In stark contrast, the second analysis shows that for the predictions produced by Northpointe, the direct effect of race is statistically significant, explaining almost a third of the overall racial disparity. Finally, in the third analysis, we show that the direct effect of race on Northpointe’s predictions was significant even in the group of individuals who did not re-offend.
Therefore, the absence of the direct effect in the true, observed outcome, and its presence in the predictions for both the overall dataset and the group of non-recidivists, indicates that the predictions produced by Northpointe are strongly racially prejudiced, and constitute a serious mistreatment of the racial minority groups.
Legal Implications
We quickly discuss some of the possible legal implications of the findings summarized above. Firstly, direct discrimination is explicitly considered in some provisions of the US legal system. For example, under the Title VII of the Civil Rights Act of 1964 (Act 1964a), disparate treatment of individuals based on race is strictly prohibited. Another example is the Fair Housing Act (Act 1964b), which also prohibits direct racial discrimination.
Interestingly, recent works in legal scholarship have started to turn to interpreting the disparate treatment doctrine in causal language (Plecko and Bareinboim 2022), in particular looking at the direct effect of the protected attribute. The analysis proposed in this work also gives a causal explanation of how the overall disparity came about, and follows from a more broad framework for causal fairness analysis, which was designed with the intention of interpreting the legal doctrines of disparate treatment and disparate impact.
However, the doctrines of disparate treatment and disparate impact would likely not be explicitly considered in a legal proceeding on the COMPAS tool. Nonetheless, the absence of a direct effect of race on the true observed outcome (Experiment A) and its presence in Northpointe’s predictions (Experiments B, C) indicate a clear issue and provide prima facie evidence of intentional racial discrimination, which is prohibited by the Equal Protection clause of the 14th Amendment of the United States Constitution.
In conclusion, our causal analysis of the COMPAS tool explains the disparities observed in the data, and demonstrates a clear direct effect of race on predictions of recidivism. As discussed above, such findings likely constitute a basis for legal action against a discriminatory practice from the software provider that produced the predictions.
References
Act, Civil Rights. 1964a. “Civil Rights Act of 1964.” Title VII, Equal Employment Opportunities.
———. 1964b. “Fair Housing Act.” Civil Rights Act of 1968 — Title VIII (Fair Housing).
Greiner, D James, and Donald B Rubin. 2011. “Causal Effects of Perceived Immutable Characteristics.” Review of Economics and Statistics 93 (3): 775–85.
Larson, Jeff, Surya Mattu, Lauren Kirchner, and Julia Angwin. 2016. “How We Analyzed the COMPAS Recidivism Algorithm.” ProPublica (5 2016) 9.
Pearl, J. 2000. Causality: Models, Reasoning, and Inference. New York: Cambridge University Press.
Plecko, Drago, and Elias Bareinboim. 2022. “Causal Fairness Analysis.” arXiv Preprint arXiv:2207.11385.
Weinberger, Naftali. 2022. “Signal Manipulation and the Causal Analysis of Racial Discrimination.”