The United States Census of 2018 collected broad information about the US Government employees, including demographic information \(Z\) (\(Z_1\) for age, \(Z_2\) for race, \(Z_3\) for nationality), gender \(X\) (\(x_0\) female, \(x_1\) male), marital and family status \(M\), education information \(L\), and work-related information \(R\).
A data scientist loads the data and performs the following initial analysis:
data <-get(data("gov_census", package ="faircause"))data <-as.data.frame(data[seq_len(20000), ])knitr::kable(head(data), caption ="Census dataset.")
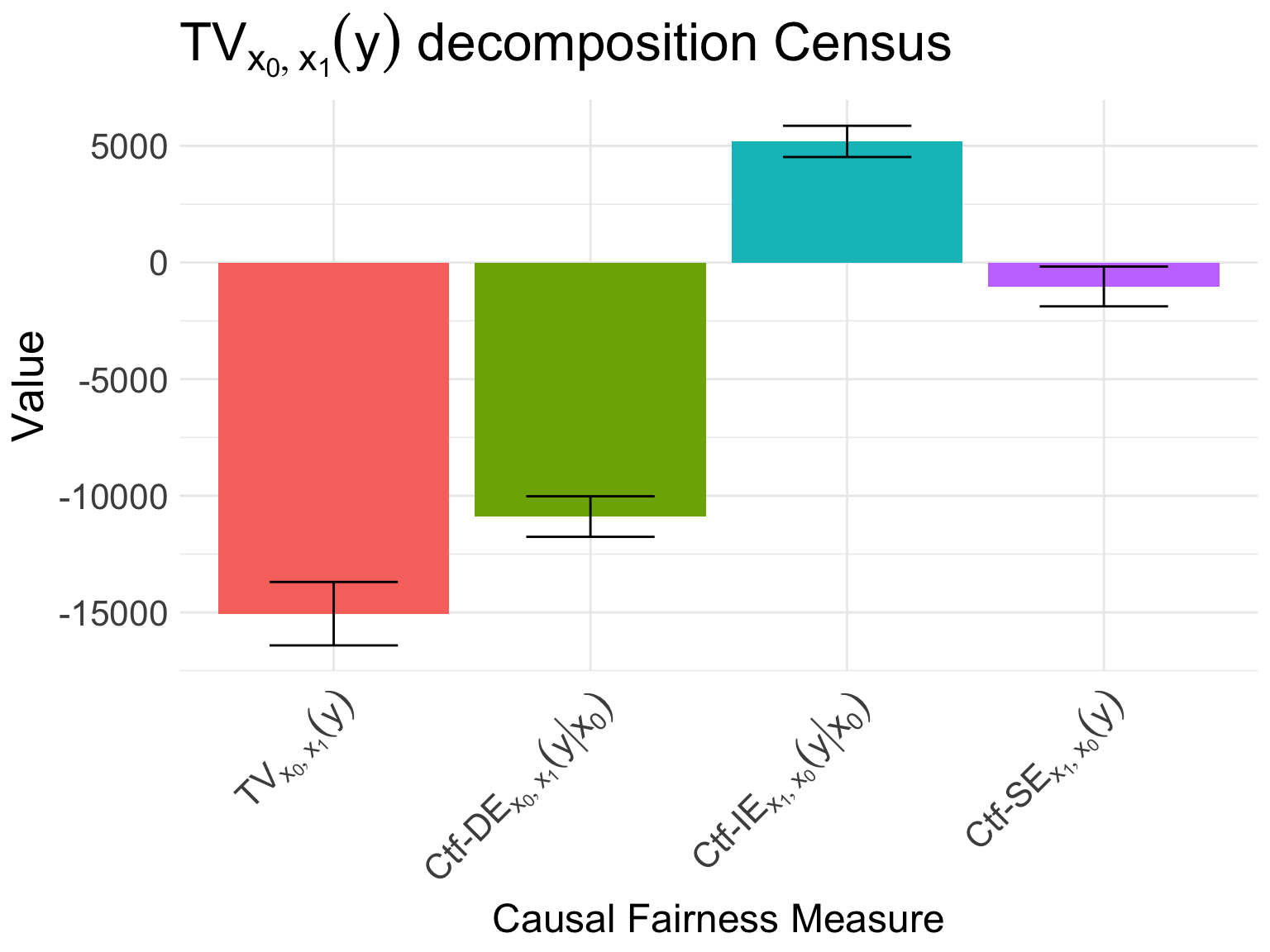
Therefore, the data scientist observed that male employees on average earn $14000/year more than female employees, that is
\(E[y \mid x_1] - E[y \mid x_0] = 15054.\)
Following the Fairness Cookbook, the data scientist does the following:
SFM projection: the SFM projection of the causal diagram \(\mathcal{G}\) of this dataset is given by \[
\Pi_{\text{SFM}}(\mathcal{G}) = \langle X = \lbrace X \rbrace, Z = \lbrace Z_1, Z_2, Z_3 \rbrace, W = \lbrace M, L, R\rbrace, Y = \lbrace Y \rbrace\rangle.
\] She then inputs this SFM projection into the faircause R-package,
The data scientist decides that the differences in salary explained by the spurious correlation of gender with age, race, and nationality are not considered discriminatory. Therefore, she tests the hypothesis \[H_0^{(x\text{-IE})}: x\text{-IE}_{x_1, x_0}(y \mid x_0) = 0,\] which is rejected, indicating evidence of disparate impact on female employees of the government. The measures computed in this example are visualized in Figure 1.